
2025 年 9 月 26 日,韓國「國家資訊資源管理院」(NIRS)的大田資料中心發生嚴重火災,一顆老化鋰電池爆炸引發全面性延燒,導致政府專用雲端儲存系統 G-Drive 全部毀損。
事件造成 75 萬名公務員、長達 7 年、約 858 TB 資料 在一夜之間消失。官方坦言該系統「完全無外部備份」,震驚全球 IT 界。
這起事故讓我們不得不重新審視:「若要建構一個同等級(數百 TB 、數十萬用戶)的文件共用系統,該如何避免重蹈覆轍?」
🔍 災難重點回顧
- 火源:老化鋰電池爆炸,引燃伺服器機櫃。
- 受損系統:政府雲端 G-Drive (2018 年起用)。
- 資料規模:約 858 TB,19 萬–75 萬 名公務員使用。
- 致命缺陷:無外部備份、集中單點、消防與隔離設計不足。
- 損失結果:所有雲端文件燒毀,業務系統全面中斷。
🧱 我們如何正確設計一個 G-Drive 級文件儲存系統
若重新設計同規模系統(75 萬用戶、800 TB 可用容量),
可採以下分層架構:
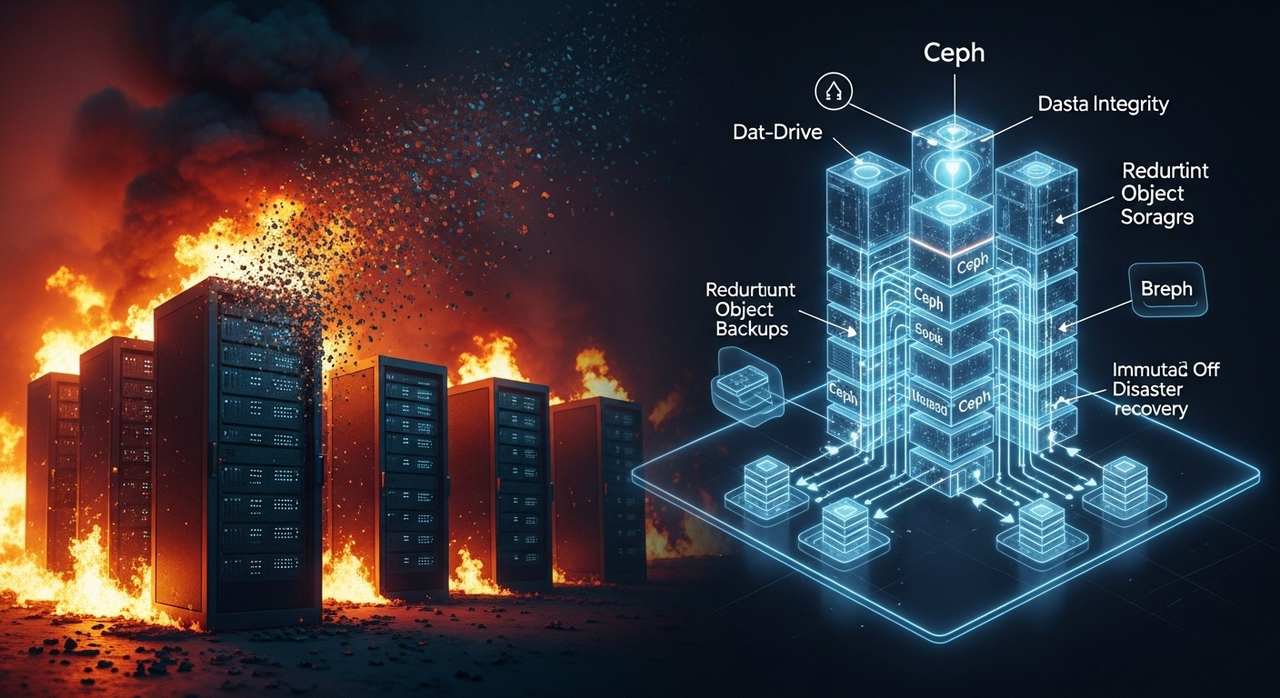
1️⃣ 儲存層:Ceph 物件儲存(RGW S3 介面)
| 類別 | 推薦值 |
| 編碼策略 | EC 8+3 (11/8 開銷 ≈ 1.375×) |
| 每站原始容量 | 約 1.4 – 1.6 PB |
| 節點配置 | 12 台 OSD 節點、每台 12–16 顆 20–22 TB HDD + 2 顆 NVMe WAL/DB |
| 網路 | 25 – 100 GbE Cluster 網、公私分離 |
| Pool 示例 | default.rgw.buckets.data (EC)、default.rgw.buckets.index/meta/log (三副本) |
2️⃣ 跨站複寫:RGW Multisite 近即時異地備援
- 架構:一個 Realm、兩個 Zone(主 zone-a 與 備 zone-b)。
- 同步機制:物件與中繼資料非同步複寫。
- RPO:秒級至數分鐘(取決於 WAN 頻寬)。
- RTO:數分鐘至十餘分鐘(DNS / App 切換)。
核心指令範例:codeBash
# 建立 EC Profile
ceph osd erasure-code-profile set ec-8-3 k=8 m=3 crush-failure-domain=host
# 建立資料池
ceph osd pool create default.rgw.buckets.data 8192 8192 erasure ec-8-3
# 建立 multisite 架構
radosgw-admin realm create --rgw-realm=gdrive --default
radosgw-admin zonegroup create --rgw-zonegroup=global --master --default
radosgw-admin zone create --rgw-zone=zone-a --master --default \
--endpoints=https://rgw-a1.example.com --access-key=KEYA --secret-key=SECA
radosgw-admin zone create --rgw-zone=zone-b \
--endpoints=https://rgw-b1.example.com --access-key=KEYB --secret-key=SECB
radosgw-admin period update --commit🗺️ 拓樸圖
codeCode
Users → [LB] → RGW-A → Ceph Cluster A (EC 8+3)
│
│ RGW Multisite Sync(非同步複寫)
▼
RGW-B → Ceph Cluster B (EC 8+3)🧩 應用層整合
- 前端:Nextcloud Enterprise / Seafile Pro / 自研 API
- 身分:Keycloak / LDAP / SAML / OIDC
- 資料庫:PostgreSQL 叢集 + 邏輯複寫
- 快取:Redis Cluster
- 監控:Prometheus + Grafana + Loki
🔐 備份與安全
- 複寫 ≠ 備份,需另建 Immutable 離線備份(rclone → 雲冷存 Glacier 類)。
- 每日增量、每週全備,保留 90 – 180 天版本。
- 啟用 Versioning、Lifecycle、Object Lock、加密金鑰集中管理(Vault/KMIP)。
🌐 網路與效能估算
- 每日變更 1% ≈ 8 TB/day → 平均 93 MB/s → 建議 10 – 40 Gbps 專線。
- 叢集內部 :25 – 100 GbE 骨幹; 跨站延遲 ≤ 20 ms 可達秒級 RPO。
💰 成本概算(以 5 年攤提)
| 項目 | 單站月成本 | 兩站月成本 |
| 硬體攤提 | 5.2 – 7.5 K USD | 10.4 – 15 K USD |
| 機櫃電力 | 2 – 5 K USD | 4 – 10 K USD |
| 專線 / WAN | 3 – 10 K USD | 3 – 10 K USD |
| 維保支援 | 2 – 6 K USD | 2 – 6 K USD |
| 總計 | — | 約 19 – 41 K USD/月 |
✅ 實作重點清單
- EC 8+3 池 + 三副本 metadata 池。
- RGW Multisite 正確設置並監控 sync lag。
- S3 端啟用 Versioning 與 Lifecycle。
- 獨立 Immutable 備份與季度 DR 演練。
- 監控 PG/OSD 健康、延遲、回填。
- MFA/SSO 安全控管、日誌稽核、行為偵測。
🔎 結語:從 G-Drive 學到的教訓
韓國政府的災難揭示了兩個關鍵真相:
- 集中式、無備份的系統終將失敗。
- 備援、演練、版本控制與異地容災是唯一的保險。
若當時 G-Drive 採用 Ceph RGW Multisite 或任何具備 versioning 與 off-site backup 的設計,
即使機房全毀,資料亦可在數分鐘內於備站恢復。
這不只是技術問題,更是組織決策與治理問題。
發佈留言