
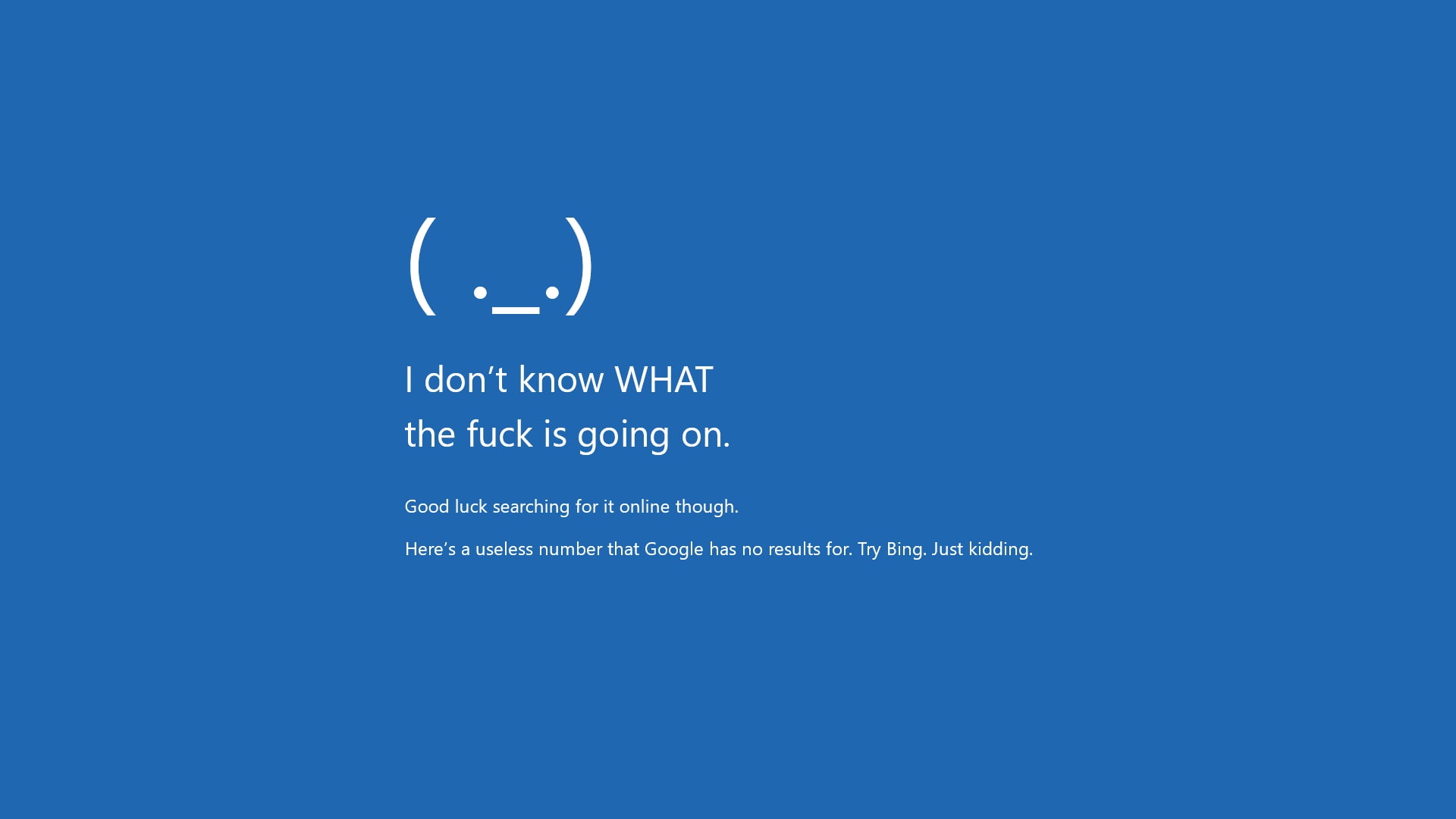
在生成式 AI 的浪潮下,「由圖生成 UI」的能力逐漸成為一個熱門應用場景。設計師或工程師能透過這樣的技術,將一張設計稿或草圖,快速轉化為 HTML/CSS 網頁原型,節省大量人力與時間。
為了測試這些 AI 模型在實際任務中的表現,我做了一個小實驗專案 —— bsod-page,並已部署在 bsod.windo.me,讓大家可以直接線上體驗。
這個實驗的做法很單純:
👉 給模型一張模仿 Windows BSOD 的 meme 圖,讓它們嘗試輸出完整的 UI 網頁。
測試模型
這次比較了五個不同的 AI 模型,涵蓋 Anthropic、Google 與 OpenAI:
- Claude Sonnet 4 —— Anthropic 最新旗艦模型。
- Claude Code —— Anthropic 專門強化程式碼的模型。
- Gemini 2.5 Flash —— Google 的高速模型,強調低延遲。
- Gemini 2.5 Pro —— Google 的高階模型,側重複雜推理與理解。
- OpenAI GPT-5 —— OpenAI 最新一代模型,綜合語言、程式與多模態生成能力。
比較面向
為了觀察不同模型的差異,我將結果從以下五個面向來檢視:
| 面向 | 評估重點 |
|---|---|
| 視覺貼近度 | 顏色、字體、排版是否與 meme 相符? |
| 結構還原能力 | 能否正確區分標題、文字、表情符號與進度條? |
| 語義理解 | 模型是否理解哪些內容是錯誤訊息、哪些是附加說明? |
| 互動性/可用性 | 是否輸出完整 HTML/CSS,能作為網頁使用? |
| 細節還原 | 尤其是表情符號、文字對齊等小細節是否正確? |
實驗結果
1. Claude Sonnet 4
- 能輸出 HTML,但格式不完全正確。
- 表情符號無法正確還原。
- 文字沒有靠左對齊,而是置中顯示。
- 雖然能展示,但與 meme 差距明顯。
2. Claude Code
- 結構清晰,但也有偏差。
- 背景顏色選擇錯誤,與 meme 不一致。
- 同樣存在 文字置中、表情符號錯誤 的問題。
- 語法乾淨,但在外觀忠實度上表現不佳。
3. Gemini 2.5 Flash
- 能正確生成可展示的網頁。
- 文字被置中,非靠左對齊。
- 表情符號還原稍微有落差。
- 有趣的是,還原度反而比 Pro 更高,更接近 meme。
4. Gemini 2.5 Pro
- 同樣能生成可展示的網頁。
- 文字置中,表情符號不夠精確。
- 雖然理解力理應比 Flash 更強,但在這次測試中,還原度比 Flash 低。
5. OpenAI GPT-5
- 唯一能完整正確輸出的模型。
- HTML/CSS 結構清晰、正確。
- 文字正確靠左對齊,樣式高度還原 meme。
- 表情符號完全正確,細節精準。
- 可直接作為網頁使用,效果最佳。
總結
- OpenAI GPT-5 是唯一能正確生成「格式、對齊與表情符號」的模型,忠實度與實用性最高。
- Claude 系列 雖能生成 HTML,但普遍存在文字置中與表情符號錯誤,Claude Code 還選錯背景顏色。
- Gemini 系列 能生成可展示的網頁,但文字置中、表情符號不足;Flash 還原度竟比 Pro 更高。
- 整體而言,GPT-5 在「由圖生成 UI」任務上明顯領先其他模型。
這也意味著,未來若要讓「圖生 UI」更成熟,可能需要 結合不同模型的優勢 —— 一個專注語義結構,一個專注排版與美感,最終融合成完整的可用結果。
👉 想親眼看看比較結果?
bsod.windo.me
發佈留言